《图解HTTP》读书笔记
基本概念
HTTP协议是TCP/IP协议族中应用层的一种协议,也可以说是现在Web中应用最广泛的一个协议了。
TCP/IP 协议族
为了更加清晰地理解HTTP,有必要先了解一下它所处的TCP/IP协议族。就像人和人之间的交流合作需要协议来规范一样,网络中的计算机也是同理: 从电缆的规格到IP地址的选定方法、寻找异地用户的方法、双方建立通信的顺序,以及Web页面显示需要处理的步骤……这些一系列规则都需要实现制定好, 才能让网络中千千万万的计算机之间的交流不会乱套。这些一系列的「规则」就构成了TCP/IP协议族。
分层是软件工程里一个非常重要的思想,这样的架构具有清晰易扩展的优点,层内部的变化不会影响到其它层,TCP/IP协议族就采用了分层的思想,自上而下分成了四层:
应用层,传输层,网络层,链路层,每一层的协议只约定了特定的功能,HTTP就位于应用层。利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信。发送端从应用层往下走,接收端则往应用层往上走。一次HTTP请求的典型过程如下图所示:
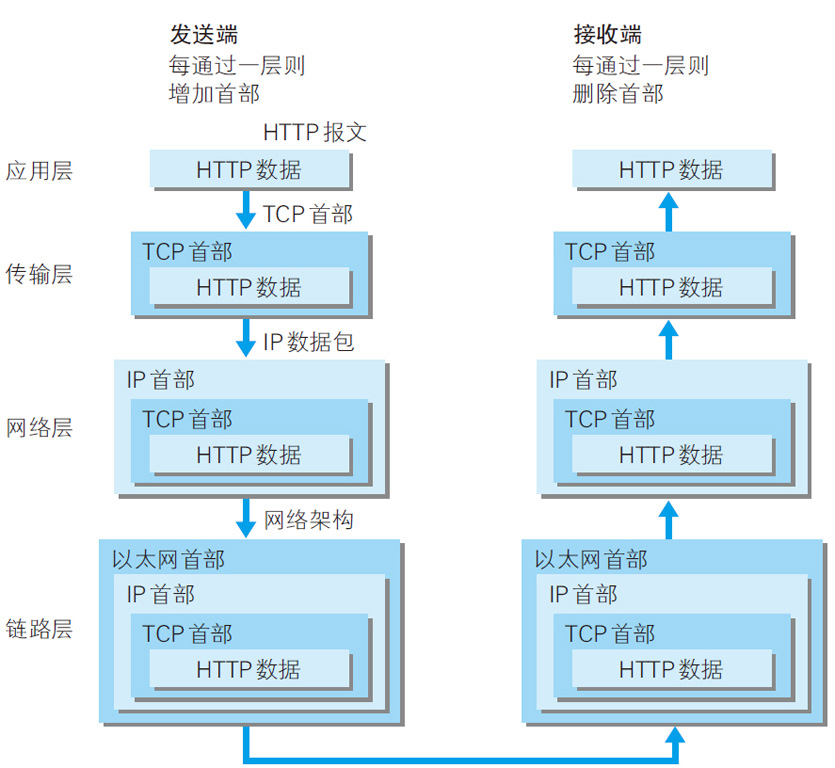 关于TCP/IP的更加详尽的内容可以参考其他资料。
关于TCP/IP的更加详尽的内容可以参考其他资料。
URI
URI是
Uniform Resource Identifier的缩写,是由某个协议方案表示的资源的定位标识符。协议方案是指访问资源所使用的协议类型名称。 采用HTTP协议时,协议方案就是http。除此之外,还有ftp、mailto、telnet、file等。
如下是一些比较常见的URI的例子:
ftp://ftp.is.co.za/rfc/rfc1808.txt
http://www.ietf.org/rfc/rfc2396.txt
ldap://[2001:db8::7]/c=GB?objectClass?one
mailto:John.Doe@example.com
news:comp.infosystems.www.servers.unix
tel:+1-816-555-1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
我们比较熟悉的URL(Uniform Resource Locator,统一资源定位符)表示资源在互联网上的地址,它其实是URI的一个子集,因为URI仅仅表示「标识」,
标识的类型有很多,比如ISBN号码,电话号码,邮箱,网页链接地址等,而URL则把概念缩小到了「地址」。
由于URI在绝大多数场景下都是以URL的形式存在,大家一般都说URL居多,这也没什么问题,但是在心里要清楚URI和URL还是有所区别的。
HTTP协议内容
接下来的内容基于HTTP 1.1版本。
请求 & 响应报文结构
在两台计算机之间使用HTTP协议通信时,在一条通信线路上必定有一端是客户端,另一端则是服务器端。HTTP协议规定,请求从客户端发出, 最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
HTTP报文本身是由多行(用CR+LF作换行符)数据构成的字符串文本。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文大致可分为报文首部和报文主体两块。 两者由最初出现的空行(CR+LF)来划分。通常,并不一定要有报文主体。
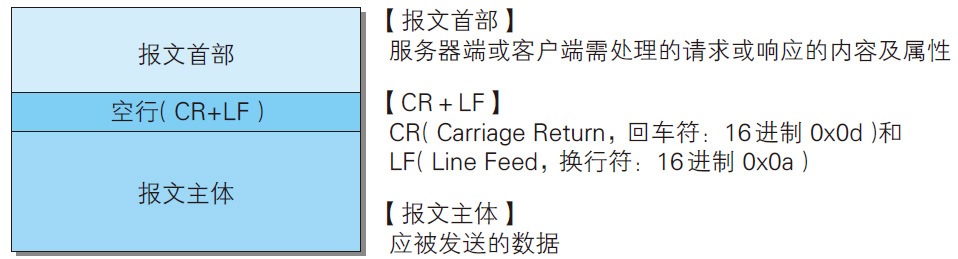
请求报文是由请求方法、请求URI、协议版本、可选的请求首部字段和内容实体构成的。响应报文基本上由协议版本、状态码(表示请求成功或失败的数字代码)、用以解释状态码的原因短语、可选的响应首部字段以及实体主体构成。
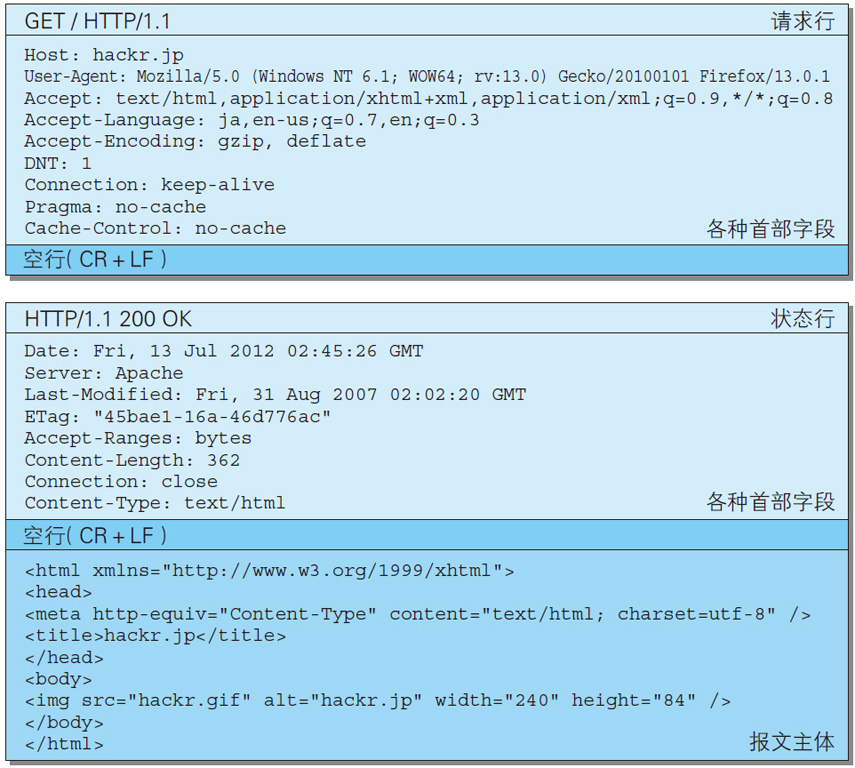
如下是一个HTTP请求和响应报文的实例:
响应状态码
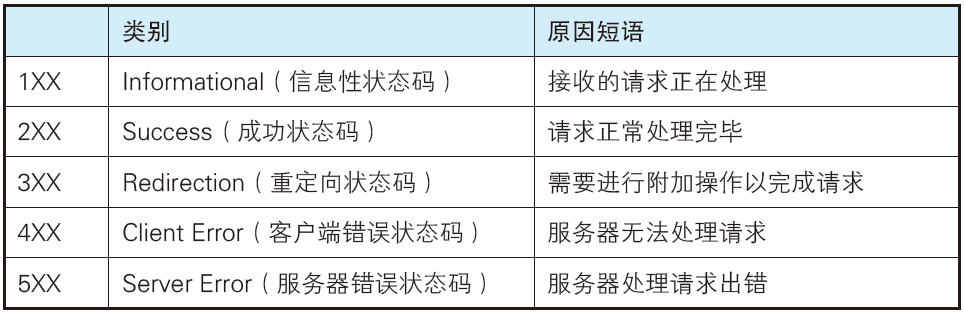
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。 数字中的第一位指定了响应类别,后两位无分类。
状态码主要类型一览:
首部 & 实体
HTTP首部字段是构成HTTP报文的要素之一。在客户端与服务器之间以HTTP协议进行通信的过程中,无论是请求还是响应都会使用首部字段,它能起到传递额外重要信息的作用。使用首部字段是为了给浏览器和服务器提供报文主体大小、所使用的语言、认证信息等内容。
HTTP首部字段由首部字段名和字段值构成的,中间用冒号“:”分隔。比如:Content-Type: text/html。
HTTP实体是HTTP请求和响应传输的主体内容,根据场景不同可能是表单参数,HTML文本,JSON文本,二进制流等。
关于报文的首部和实体的内容有很多,也是个深坑,这里就不再详细展开了,可以去翻阅文档并结合实战来加深理解, 推荐MDN上一个不错的HTTP文档站。
Cookie
HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个级别,协议对于发送过的请求或响应都不做持久化处理。 使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成如此简单的。 不可否认,无状态协议当然也有它的优点。由于不必保存状态,自然可减少服务器的CPU及内存资源的消耗。从另一侧面来说,也正是因为HTTP协议本身是非常简单的,所以才会被应用在各种场景里。
即是说,A对B发送了一千次HTTP请求,也不能把他们的距离拉近一毫米,第一千零一次请求到来时,B依旧不认得A。 但是随着HTTP的应用越来越广泛,已经超出了最初设计用来传递文档的初衷,逐渐变得越来越复杂,像是电商,社交这样的重量级Web应用都构架在了HTTP之上,这样的系统肯定有保存用户状态的需求,于是大家设计出了Cookie机制来实现。
Cookie会根据从服务器端发送的响应报文内的一个叫做
Set-Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去。服务器端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
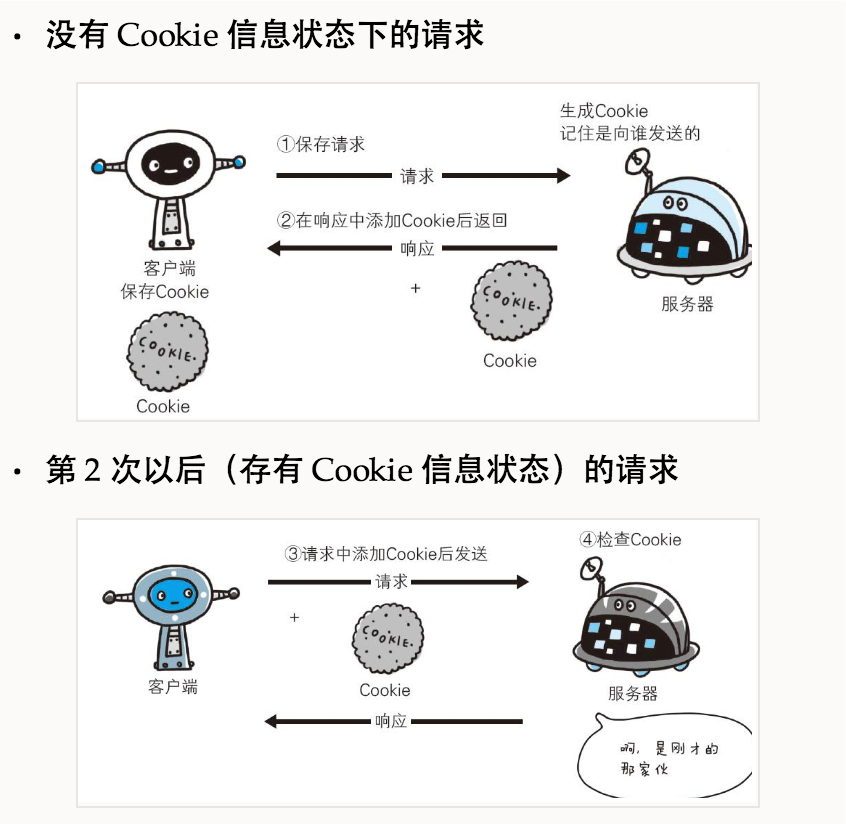
有关HTTP Cookie更加详细的介绍可以参见Wiki。
更多资料
在整理读书笔记时屯了一些学习资料 & 字典书,在这里也列一下吧: