深入理解CPU load
摘要
每一个程序员应该都对CPU load不陌生,我们在Linux系统中输入uptime或者top命令就可以看到load average,大家知道这个值代表了CPU的繁忙程度,而且是越低越好。比如下面是我在一台服务器上执行uptime命令的结果:
$uptime
21:18:53 up 176 days, 12:06, 1 user, load average: 3.76, 3.38, 3.31
load average的三个值分别代表了CPU在过去1分钟,5分钟,15分钟的平均load。
但是这个值具体的含义是什么呢?load在什么范围内才算是正常的呢?我们应该更关注三个值中的哪一个呢?还有,CPU load和CPU利用率又有什么区别呢?
为了回答上面的问题,本文将对CPU load进行较为深入的分析,首先介绍基本概念,从单核场景扩展到多核的场景;再讨论开发运维时需要关心的关键指标;最后还探讨了CPU load和CPU利用率的区别。
基本概念
关于load,Wikipedia的解释是这样的
In UNIX computing, the system load is a measure of the amount of computational work that a computer system performs. The load average represents the average system load over a period of time.
系统的Load是对于计算机系统执行计算任务数量的一种度量(注意关键词:amount,数量)。load average代表了一段时间内的系统平均load。
单核场景
首先以最简单的单核场景进行分析。
这篇文章做了一个很生动的比喻:有一座只有单车道的大桥,这座大桥能同时容纳的通车数是有上限的,假设为10。那么:
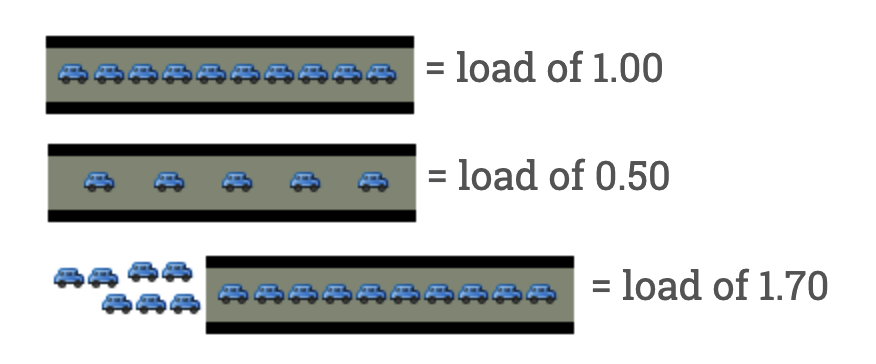
- load = 0 时,代表桥上没有车辆通行,桥完全处于空闲状态。
- load = 0.5时,代表桥上有50%的车辆,但还剩下50%的容量。事实上,只要Load还未达到1,桥就还有空余容量,所以此时如果有新的车辆到来,是可以直接上桥不用排队的。
- load = 1时,代表桥上有100%的车辆,已经没有空余,但也没有车在排队。
- load = 1.7时,代表桥上有100%的车辆,已经没有空余,而且有70%的车在排队等待上桥。事实上,只要Load大于等于1,就代表桥已经满载,所以此时如果有新的车辆到来,就需要在外面排队等待。
对应到计算机术语里来,大桥代表着CPU,汽车代表着任务,进车过桥代表着任务在使用CPU时间,汽车排队代表着任务在等待CPU分配时间片。
一个空闲CPU的 load number = 0,每一个正在使用或者等待使用CPU的任务会使 load number + 1,每一个结束的任务会使 load number - 1。系统会计算一段时间内的 exponentially damped/weighted moving average 作为load average。数学公式先抛开,只看结论的话就是,load average代表着正在使用和等待使用CPU的任务数之和。
对应上面大桥的例子,就是:
- load = 0 时,代表CPU完全空闲,没有任务执行,没有任务等待。
- load = 0.5时,代表CPU正在执行的任务量达到50%,但还剩下50%的空闲。
- load = 1时,代表CPU已经达到100%,已经没有空余,但也没有任务在排队。
- load = 1.7时,代表CPU已经达到100%,已经没有空余,而且有70%的任务在排队等待。
多核场景
单核场景理解清楚了,扩展到多核其实也很简单,把多核CPU理解为多车道大桥即可,有几个核心就对应几条车道。因为多核CPU同时能执行多个任务,所以在多核的场景下,load值只要不高于核心数即可。就像我在开始时执行的那个例子,因为那台服务器有很多个,所以即使load为3.71,CPU也是非常空闲的。
有一点需要特别说明,load的上下文里,我们只关心核心数,并不关心核心的分布,也即是:1个4核CPU = 2个双核CPU = 4个单核CPU。
关键指标
为了说明方便,以下指标以单核为例,多核场景下用load除以核心数进行换算。
因为单核CPU同一时间只能执行一个任务,所以一旦这个load值大于1就代表着有任务在等待了,请务必保持CPU load小于1。 那么是不是load只要小于1就行了呢?这样其实不太好,如果load很逼近1,就代表CPU几乎没有余量,无法应对意外情况。按照经验值来说,load维持在0.7以下是比较好的。
1分钟,5分钟,15分钟的load average应该更加关注哪一个呢?一般来说应该关注第三个,也即是15分钟平均。因为如果单单只有一个1分钟平均指标高,那很可能只是这一分钟的突发情况,而如果15分钟平均都高,那就需要引起重视了。
load average和CPU利用率的区别
还有另一个CPU指标:CPU利用率,以百分比形式表示,也能表示CPU的繁忙程度。那么这两个指标有什么区别呢?
正如前面基本概念里加粗强调的那样,CPU load是对于任务数量的度量。而CPU利用率则是: CPU使用时间 / (CPU使用时间 + 空闲时间)。
二者一般呈现正相关关系,但是也有特例:
- load average低,利用率高:如果CPU执行的任务数很少,则load average会低,但是这些任务都是CPU密集型,那么利用率就会高。
- load average高,利用率低:如果CPU执行的任务数很多,则load average会高,但是在任务执行过程中CPU经常空闲(比如等待IO),那么利用率就会低。
进程还是线程?
我读到的文章里,统计load时都是算的进程,但是我在Mac上写代码验证时发现,在同一个java进程下创建线程,也会提高load average。上网查了一下原来OSX是基于线程调度的,这也和我写代码验证的现象一致。
再结合这篇回答 说:Linux调度的是task,有可能是进程,也可能是线程。所以我认为统计load时应该是按照当前OS的CPU调度的基本单位来算的,可能是进程,也可能是线程。所以为了严谨起见,我就把上文中所有出现的 进程 都改为了 任务 ,以免产生误导。
参考
- https://en.wikipedia.org/wiki/Load_(computing)#CPU_load_vs_CPU_utilization
- https://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average
- http://blog.scoutapp.com/articles/2009/07/31/understanding-load-averages
- https://stackoverflow.com/questions/15601155/does-linux-schedule-a-process-or-a-thread