深入理解CMS收集器
摘要
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。现在的互联网后端系统非常重视服务的响应速度,因此CMS收集器就很符合需求而被广泛应用。在平时的工作中难免会遇到GC方面的问题,尤其是让Java开发者头大的Full GC问题,因此深入理解CMS收集器是非常必要的。
本文先简单介绍了CMS的基本原理,阐述了CMS相关的几个关键问题,并结合实际项目分析了CMS的GC过程。不涉及GC的基本内容,需要这方面内容的读者请参考其他资料。
基本原理
正如名字所起的那样,CMS基于「标记-清除」算法,整个垃圾收集过程主要有4步:
- 初始标记(CMS initial mark):标记一下GC Roots能直接关联到的对象,速度很快
- 并发标记(CMS concurrent mark):GC RootsTracing
- 重新标记(CMS remark):修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录
- 并发清除(CMS concurrent sweep)
图示如下:
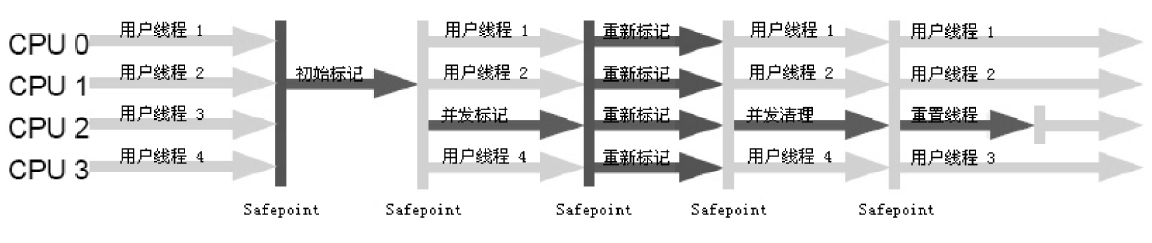
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。通过图中可以比较清楚地看到CMS收集器的运作步骤中并发和需要停顿的时间。
几个关键问题
1.CMS GC != Full GC
关于什么是Full GC以及和其他GC的区别,可以参见这个问题(https://www.zhihu.com/question/41922036)下Ted Mosby和R大的回答,我觉得非常棒。
2.对CPU资源敏感
其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。CMS默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。
在这一点上我是有过深切体会的,因为有一次就因为代码写得不好,对象创建得太多,从而导致系统频繁CMS GC甚至Full GC(关于Full GC的原因参见下面的Concurrent Mode Failure),CPU利用率也居高不下。
3.无法处理浮动垃圾
CMS并发清理时,用户程序的运行也会产生新的垃圾(一边打扫房间,一遍丢新的垃圾),但是这部分垃圾产生于标记过程之后,因此只好留在下次GC时清理,这种垃圾被称为浮动垃圾(Floating Garbage)。
4.Concurrent Mode Failure
由于CMS并发清理阶段,用户程序还在运行,也需要内存空间,因此CMS收集器不能像其他老年代收集器那样,等到老年代空间快满了再执行垃圾收集,而是要预留一部分内存给用户程序使用。CMS的做法是老年代空间占用率达到某个阈值时触发垃圾收集,有一个参数来控制触发百分比: -XX:CMSInitiatingOccupancyFraction=80 (这里配置的是80%)。
如果预留的老年代空间不够应用程序的使用,就会出现Concurrent Mode Failure,此时会触发一次FullGC,采用标记-清除-整理算法,会发生stop-the-world,耗时相当感人(实际工作中遇到的大部分FGC估计都是这种情况)。Concurrent Mode Failure一般会伴随ParNew promotion failed,晋升担保失败。所谓晋升担保,就是为了应对新生代GC后存活对象过多,Survivor区无法容纳的情况,需要老年代有足够的空间容纳这些对象,如果老年代没有足够的空间,就会产生担保失败,导致一次Full GC。
为了避免Concurrent Mode Failure,可以采取的做法是:
- 调大老年代空间;
- 调低CMSInitiatingOccupancyFraction的值,但这样会造成更频繁的CMS GC;
- 代码层面优化,控制对象创建频率。
5.空间碎片
这是「标记-清理」算法的通病,空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前触发一次Full GC。为了解决这个问题,CMS收集器提供了一个-XX:+UseCMSCompactAtFullCollection开关参数(默认就是开启的),用于在CMS收集器顶不住要进行FullGC时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。虚拟机设计者还提供了另外一个参数-XX:CMSFullGCsBeforeCom-paction,这个参数是用于设置执行多少次不压缩的Full GC后,跟着来一次带压缩的(默认值为0,表示每次进入FullGC时都进行碎片整理)。
实战分析
当老年代占用率达到阈值时,会触发CMS GC回收老年代(注意不是Full GC),下图是一台生产环境机器的堆内存占用图,展示了这样的规律性。

从图中最左边可以看出00:56时,堆空间有过一次下跌,上机器看了下gc日志,果然有一次CMS GC:
2018-02-26T00:56:18.863+0800: 2195763.702: [GC [1 CMS-initial-mark: 2517403K(3145728K)] 2572373K(5033216K), 0.0451750 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
2018-02-26T00:56:18.908+0800: 2195763.747: [CMS-concurrent-mark-start]
2018-02-26T00:56:19.064+0800: 2195763.903: [CMS-concurrent-mark: 0.155/0.155 secs] [Times: user=0.19 sys=0.00, real=0.16 secs]
2018-02-26T00:56:19.064+0800: 2195763.903: [CMS-concurrent-preclean-start]
2018-02-26T00:56:19.073+0800: 2195763.912: [CMS-concurrent-preclean: 0.008/0.009 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
2018-02-26T00:56:19.073+0800: 2195763.912: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2018-02-26T00:56:24.370+0800: 2195769.209: [CMS-concurrent-abortable-preclean: 5.293/5.297 secs] [Times: user=5.96 sys=0.00, real=5.29 secs]
2018-02-26T00:56:24.372+0800: 2195769.211: [GC[YG occupancy: 184177 K (1887488 K)]2195769.211: [Rescan (parallel) , 0.0402610 secs]2195769.252: [weak refs processing, 0.2033920 secs]2195769.455: [class unloading, 0.0089200 secs]2195769.464: [scrub symbol table, 0.0092210 secs]2195769.473: [scrub string table, 0.0011210 secs] [1 CMS-remark: 2517403K(3145728K)] 2701580K(5033216K), 0.2687490 secs] [Times: user=0.39 sys=0.00, real=0.26 secs]
2018-02-26T00:56:24.642+0800: 2195769.481: [CMS-concurrent-sweep-start]
2018-02-26T00:56:28.470+0800: 2195773.309: [CMS-concurrent-sweep: 3.829/3.829 secs] [Times: user=4.52 sys=0.00, real=3.82 secs]
2018-02-26T00:56:28.471+0800: 2195773.310: [CMS-concurrent-reset-start]
2018-02-26T00:56:28.483+0800: 2195773.322: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
结合日志分析CMS GC的过程:
- initial-mark:初始标记,只标记GC Root直接可达的对象,该过程需要Stop-The-World,耗时0.04s。可以看出老年代占用:2517403K(3145728K),算出阈值是80%,去机器上验证了一下,果然配了-XX:CMSInitiatingOccupancyFraction=80。总的堆占用:2572373K(5033216K)。
- concurrent-mark:并发标记,和应用程序并发进行,根据上一步标记的对象,进行GC Root Tracing,标记出所有可达的对象,耗时0.16s,比较短,估计可达的对象不是很多。
- concurrent-preclean:并发预清理,和应用程序并发进行,该阶段检查并发标记阶段时从新生代晋升的对象,或新分配的对象,或被应用程序线程更新过的对象,通过并发地重新扫描这些对象,预清理阶段可以减少下一个stop-the-world 重新标记阶段的工作量。耗时0.01s。如果在此之后,Eden的占用量 > CMSScheduleRemarkEdenSizeThreshold(默认为2M),会启动CMS-concurrent-abortable-preclean。
- concurrent-abortable-preclean:可终止的预清理,和应用程序并发进行,至到Eden区占用量达到CMSScheduleRemarkEdenPenetration(默认50%),或达到5秒钟。这次实际耗时5.29s,看来是达到了时限。
- remark:重新标记,该过程需要Stop-The-World,耗时0.25s。重新标记时老年代的占用没有变化,但是总的堆占用变成了2701580K(5033216K),增加的部分是新生代的。
- concurrent-sweep:并发清理,和应用程序并发进行,耗时3.82s。
- concurrent-reset:重新初始化CMS内部数据结构,以备下一次GC使用,和应用程序并发进行,耗时0.02s。
全程耗时约10秒,其中只有步骤1和6的0.3秒是阻塞的,其余带 concurrent- 的都不需要中断应用程序,可以说是完美兑现了低停顿的承诺,当然代价是并发清理时会占用更多的CPU资源,联想之前的CPU占用率过高事件:FC-Push 90% CPU问题 。
参考资料
- 《深入理解Java虚拟机》
- http://blog.csdn.net/a417930422/article/details/16948933
- http://ifeve.com/jvm-cms-log/
- https://www.zhihu.com/question/41922036