深入理解字符编码
一、前言
字符编码这个问题,困扰了无数程序员,一不小心就会掉进坑里,每当在开发中遇到乱码或者emoji表情符的奇怪问题时总是让人头疼不已,本文就来从根源上研究一下字符编码的本质和原理。
二、什么是编码
编码,就是信息从一种形式转换为另一种形式的过程(其逆过程称为解码)。
那么什么情况下需要编码呢?我们来看下面的例子:
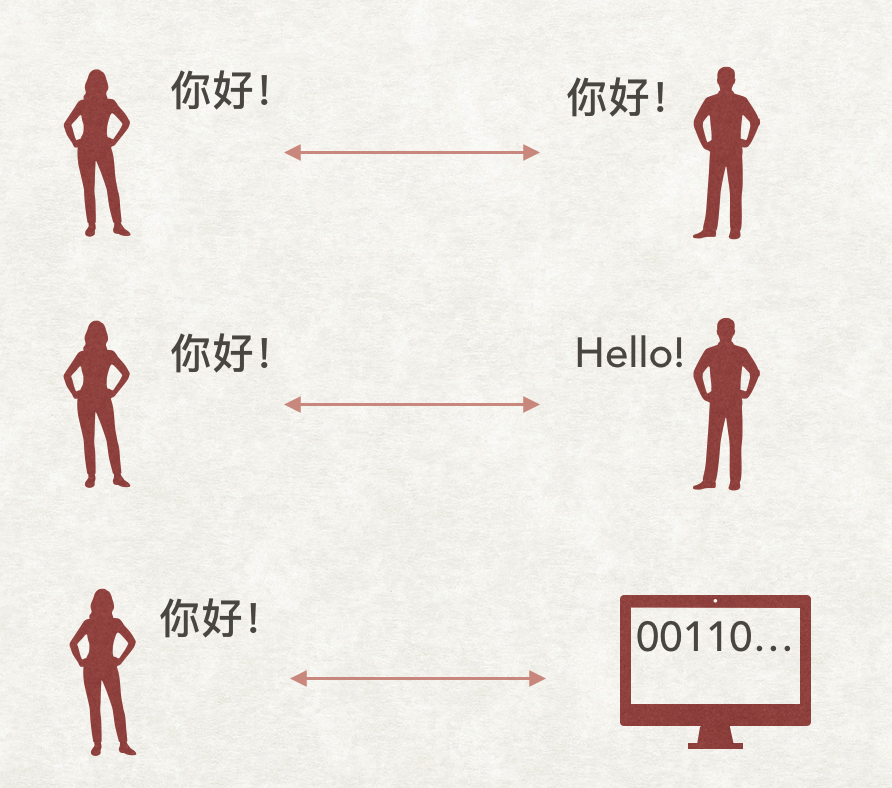
- 两个说普通话的中国人进行交流时,因为信息的形式都是中文,所以不需要编码,一个人说「你好」,另一个就能直接听明白意思,反之亦然。
- 一个中国人和美国人交流时,因为信息的形式不同,一方是中文,另一方是英文,为了准确传达信息,就需要进行编码(我们称之为翻译)。
- 一个人类和计算机交流时,也是同理,大家都知道信息在计算机中的存在形式是二进制0和1,因此为了从人类语言到二进制传达信息,需要进行编码。反之,把信息从二进制中解析为人类语言的过称,叫做解码。
清楚了什么是编码,为什么要编码,接下来看下怎么编码。
三、怎么编码
1. ASCII
一种直观的想法就是,像编字典一样,制作一个映射表,把人类语言和计算机二进制对应起来就行了。 这样的思想就孕育出了ASCII(American Standard Code for Information Interchange),如下表所示,因为是美国人设计的,所以只有常用英文字符和一些控制字符:

当我们想要编码一个字符时,只要查上表查到对应的数字;解码时同理,根据数字查到对应的字符。非常简单方便,于是我们人类就可以和计算机愉快的交流了。
但是 ASCII 也存在一些问题:
- 如何表示一些欧洲语言独有的字符(如:Café 里的 é )?
这个难不倒程序员,因为大家发现,一个字节最多能存储 256 种数字,而 ASCII只用到 0-127,其实是有冗余的,因此可以使用 128-255 的区间进行自定义。
但是不同语言设计了不同的定制规则,导致128-255区间十分混乱,跨语言编解码困难,不得不写一堆复杂的适配逻辑。 - 更大的问题:东亚语言中的字符种类成千上万种,一个字节装不下了!
于是各国又开始自己造轮子,比如中国自己设计了一套区位码,来支持中文语言体系,并由此诞生了GBK编码。但是这些编码方式和国际上的各种编码又不兼容了,更加加剧了混乱的局面。
人们就在思考,能不能把世界上的编码统一起来,从而实现多语言的流畅交流?
2. Unicode
于是 Unicode 应运而生,它的使命很宏大:编码这个星球上有史以来所有的的字符。其实本质思想其实和 ASCII 并无二致,它只是一张更大的映射表,总共可编码 1114112 个字符。 现行最新版本 Unicode 12.1,一共分配了 137,994 个字符,只用了10%左右。
2.1 Code Point 和 Plane
Unicode 为每个字符分配了一个全局唯一识别码,称为:Code Point。其取值区间为:U+0000~U+10FFFF(Code Point 描述时以 U+ 前缀)。
Code Point 一共划分为17个区域,称为平面(Plane),每个平面分配了16位,可以容纳 2^16 = 65536 个字符。 Plane0 被称为BMP(Basic Multilingual Plane),现在世界上的绝大多数语言的常用字符都在BMP上。
小贴士:看 Code Point 的 U+??XXXX 的 ?? 部分,就能知道它落在哪个平面上。比如:U+597D 在0号平面,即BMP上,U+2B7D2 则在2号平面上。
Unicode 平面分配情况如下图所示:

- 蓝色:已分配的 Code Point;
- 白色:未分配;
- 绿色:私域,不分配;
- 红色:UTF-16 Surrogate 区域,不分配,下文会讲到;
可以看出现在用的比较多的是前三个平面上,它们的详细分配情况如下所示,其中浅蓝色部分的是汉字,占据了好大一块区域,常用字在BMP,生僻字在Plane2(这会导致汉字实际编码后的存储字节数不同,后面详述):

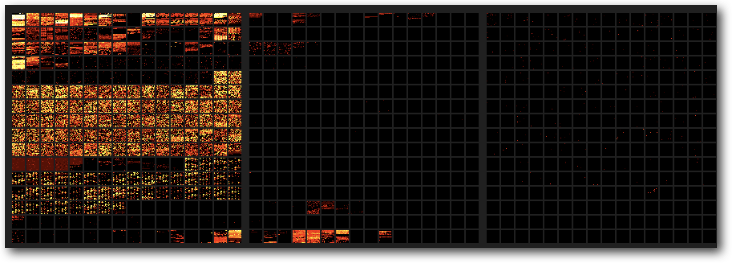
再来看一下前三个平面的使用热度图,可以看出用的最多的还是BMP,Plane1下面那一小块活跃区是emoji,随着最近网络上的走红用得也很多(但也带来了很多让程序员们头痛的问题):
2.2 Code Point 存储方案
特备注意,Unicode 里定义的 Code Point 只是一个概念,并没有规定实际落到磁盘或者内存上的时候应该如何存储,所以在具体方案上,先后出现了几种不同的方式:
- 早期简单方案(UCS-2):一开始 Unicode 字符集并不大,因此可以使用固定的2个字节直接存储 Code Point 值,但很快就不够用了。
- 四字节直接存储(UTF-32):四字节可以存储所有的 Code Point,但是这会造成常用字符前边带一大串000000……需要的存储空间相比原来翻了2到3倍,没人愿意用。
这就导致了很长一段时间里,Unicode 标准推出来了,但是没多少人用的尴尬场景,直到变长编码方式的出现,这种局面才得以改观。
变长编码的核心设计思想是:如果是常用字符,使用较少字节来存储,不常用字符则使用更多的字节来存储(这其实和 Huffman 编码的思想是一样)。 这样一来就解决了存储效率过低的问题,Unicode 才真正普及开来。
变长编码中的佼佼者是 UTF-16(16-bit Unicode Transformation Format) 和 UTF-8(8-bit Unicode Transformation Format),接下来详细讲一下它们。
3. UTF-16
Java 采取的编码方式,以16位作为一个最小编码单元(Code Unit)。所谓编码单元,就是一种编码方式里,最小不可分割的单元,最终编码结果一定是整数个编码单元。

Code Point 编码规则:
- 在 0x0000-0xFFFF 中的(即BMP),直接用一个编码单元表示。
- 在 0x10000-0x10FFFF 中的,使用一对编码单元共同表示,称为代理(Surrogates,前面的叫 High Surrogate,后面的叫 Low Surrogate)。
UTF-16编码实例:
- 编码「好」(常用字,在 BMP 上):
- 查 Unicode 表可知,Code Point 值为 U+597D
- 查 UTF-16 编码规则表,该值落在 0x0000-0xFFFF 中,此时可以直接存储,因此编码之后的值为 0x597D。
- 编码「𫟒」(一个古汉语生僻字,在 Plane 2上),编码过程示意图如下:

- 查 Unicode 表可知,Code Point 值为 U+2B7D2
- 查 UTF-16 编码规则表,该值落在 0x10000-0x10FFFF 中,此时需要拆分为两个编码单元进行存储
- 首先把 Code Point 转为二进制:
0010 1011 0111 1101 0010 - 然后减去 0x10000 的偏移量:
0001 1011 0111 1101 0010 - 把这20位拆成前后各10位,放到 UTF-16 的 Surrogates 里:110110
0001101101, 1101111111010010 - 用16进制展示即为:0xD86D 0xDFD2
可以看出,同样是汉字,UTF-16 编码后,「好」占用2字节,「𫟒」占用4字节。
解码过程就是把上面的操作反过来执行一遍,不再赘述。
4. UTF-8
当今互联网最常用的编码方式,通行于各种网络信息的传输中,以8位为一个编码单元,即一个字节。

Code Point 规则:
- 对于单字节的字符,字节的第一位设为0,后面7位为这个符号的 Code Point 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的,这个特性对于原先使用 ASCII 编码的文本来说非常友好。
- 对于n字节的字符(1 < n <= 4),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,共同组成这个符号的 Code Point。
UTF-8 编码实例:
- 编码「好」(常用字,在 BMP 上):
- 查 Unicode 表可知,Code Point 值为 U+597D
- 查 UTF-8 规则表,该值落在 0x0800-0xFFFF 中,此时需要3个字节存储
- 转为二进制:
0101 1001 0111 1101 - 放到 UTF-8 的三个字节里:1110
0101, 10100101, 10111101 - 用16进制展示位:0xE5A5BD
- 编码「𫟒」(一个古汉语生僻字,在 Plane 2上),编码过程示意图如下:

- 查 Unicode 表可知,Code Point 值为 U+2B7D2
- 查 UTF-8 规则表,Code Point 落在 0x10000-0x10FFFF,因此需要4个字节存储
- 转为二进制:
0010 1011 0111 1101 0010 - 放到 UTF-8 的四个字节里:11110
000, 10101011, 10011111, 10010010 - 用16进制展示位:0xF0AB 0x9F92
可以看出,UTF-8 编码后,「好」占用3字节,「𫟒」占用4字节。
解码同样反过来执行一遍即可,不再赘述。
四、编码实战
接下来介绍几个和实际开发中经常遇到的几个编码问题。
1. 乱码
乱码的本质原因:编码和解码使用了不同的方式。
写一段代码进行演示:
String s = "好";
byte[] bytes = s.getBytes(StandardCharsets.UTF_16BE); // BE代表的是 Big Endian,高位在前的字节序
for (byte b : bytes) {
System.out.print(Integer.toHexString(b & 0xFF) + " ");
}
System.out.println();
System.out.println(new String(bytes, StandardCharsets.UTF_8));
步骤说明:
- 使用 UTF-16 编码「好」,得到的字节数组是:0x597D
- 转为二进制形式:0101 1001 0111 1101
- 使用 UTF-8 进行解码,识别为两个单字节编码:0101 1001 和 0111 1101,真正存储 Code Point 的部分是后7位:101 1001 和 111 1101,十六进制为 U+59 和 U+7D
- 查 Unicode 表可知,这两个 Code Point 对应的字符为:「Y}」 。
于是字符 「好」,经过 UTF-16 编码,再使用 UTF-8 解码,得到了「Y}」这么一个奇怪的结果。 可以把字符换成「𫟒」进行相同的测试,结果发现有些 UTF-16 编码出来的字节根本不符合 UTF-8 规则,无法解码,会被展示为未知字符:「�m��」,这就是我们通常所说的乱码了。
2. Java 中的字符
Java 使用 UTF-16 编码,char 类型的长度为16位,代表一个 UTF-16 编码单元,根据前面关于 UTF-16 的分析可知,一个字符可能使用1-2个编码单元进行编码,因此一个字符可能对应1或2个Java char。 也即:Unicode 字符 = Code Point ≠ Java char。
如下代码验证了上述逻辑:
String s = "\uD86D\uDFD2"; // 𫟒
System.out.println(s + ", length:" + s.length()); // String 的 length 方法返回的是 char 的个数,并非 Unicode 字符个数
for (char c : s.toCharArray()) { // toCharArray 方式获得的是 char 数组,非 Unicode 字符 / Code Point 数组
System.out.print(c + ", hex:");
System.out.println(Integer.toHexString(c));
}
// output:
// 𫟒, length:2
// ?, hex:d86d
// ?, hex:dfd2
- 字符串截取问题
subString 方法截取子串时是以 char 的下标为基准的,而我们已经知道了一个字符可能由1-2个char来存储,如果截取时不考虑这一点,就很容易出问题:
看下面这个例子:
String s1 = "\uD86D\uDFD2小青童鞋"; // 𫟒小青童鞋
System.out.println(s1.substring(0, 3));
String s2 = "小青\uD86D\uDFD2童鞋"; // 小青𫟒童鞋
System.out.println(s2.substring(0, 3));
因为「𫟒」字占两个char,所以试图使用 subString 截取「𫟒小青童鞋」的前三个字符时,会得到「𫟒小」的结果;
而截取「小青𫟒童鞋」时,则会得到「小青?」的结果,这是因为「𫟒」字的两个 char 被拦腰截断了,而截断后的第一个 char,Java 无法按照 UTF-16 的规则解码,就展示为了问号。
想要正确截断字符串,需要利用 offsetByCodePoints(int index, int codePointOffset) 方法,该方法会从 index 位置开始,往后移动 codePointOffset 个 Unicode 字符,代码如下:
private static String rightSubString(String s, int begin, int end) {
int realBegin = s.offsetByCodePoints(0, begin);
int readEnd = s.offsetByCodePoints(0, end);
System.out.println("real begin:" + realBegin + ", real end:" + readEnd);
return s.substring(realBegin, readEnd);
}
特别注意:如果字符串截取不规范,把2个char的字符从中截断了,然后再用 FastJSON 进行序列化时,就会抛出 com.alibaba.fastjson.JSONException: encodeUTF8 error 。
这是因为FastJSON 在序列化 Java 字符串时采取了比较严格的校验,一旦发现不合 UTF-16 规则的,就会抛出异常,详细原因可以参见代码 com.alibaba.fastjson.util.IOUtils#encodeUTF8 。
3.MySQL 中的 UTF-8
UTF-8 设计是能支持所有的 Unicode 字符的,但是在MySQL里实现的 utf8 最长只支持3个字节,如果向一个编码为 utf8 的列中插入一个四字节编码的字符时,就会报类似Incorrect string value: '\xF0\xAB\x9F\x92 ...' for column 'name'
这样的错。
我之前有一种误解,是以为只有插入emoji时才会报这个错,但其实理解了原因就会知道,只要字符不在BMP平面里都会出错,比如上例就是尝试向一个 utf8 编码的列中插入「𫟒」时的报的错。
解决方案:
- 正面解决:修改对应列的编码格式为: utf8mb4。
- 不方便修改表时的迂回方案:代码里手动剔除非 BMP 字符后再存储。在 Java 里可以利用
Character.isSurrogate()方法,该方法会识别一个 Java char 是否是 UTF-16 代理,如果是,则说明接下来它存储的字符不在 BMP 里。 代码如下:public static String filterNonBmpCharacters(String s) { StringBuilder sb = new StringBuilder(); for (char c : s.toCharArray()) { if (!Character.isSurrogate(c)) { sb.append(c); } } return sb.toString(); }